From the Transistor
Computers are made of transistors. A transistor is a digital switch.
Gate
Source
Sink
There are two kinds of transistors in computers: PMOS and NMOS. PMOS transistors allow current
to flow when the gate is off. NMOS transistors allow current to flow when the gate is on.
PMOS
(p-channel metal oxide semiconductor)
Gate
Source
Sink
NMOS
(n-channel metal oxide semiconductor)
Gate
Source
Sink
Logic Gates
PMOS and NMOS transistors form logic gates. Here's a two-transistor NOT gate:
Source
Input
Output
Ground
Truth table
| Input | Output |
|---|---|
| 0 | 1 |
| 1 | 0 |
Symbol
The top transistor is a PMOS as indicated by the circle, and the bottom transistor is an NMOS.
It's called a NOT gate, because the output is the opposite of the input.
Why does a NOT gate require two transistors? Isn't a PMOS transistor already a NOT gate?
The NMOS transistor ensures that when the input is 1, the output current escapes to Ground,
which "pulls down" the output to zero.
Here are the other simple logic gates:
AND
| A | B | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Symbol
OR
| A | B | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
Symbol
NAND
| A | B | Output |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Symbol
NOR
| A | B | Output |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 0 |
Symbol
XOR
| A | B | Output |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Symbol
XNOR
| A | B | Output |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Symbol
Flip-Flops
Flip-flops are circuits that store data. Computers commonly use D Flip-Flops for memory. A D
Flip-Flop consists of four NANDs and a NOT:
D
Clock
Enable Write
Q
not Q
Take some time to understand the D Flip-Flop.
If Enable Write is off, the Q output retains its value. If Enable Write is on, a clock tick
stores the D input in the Q output. The D Flip-Flop is a single-bit storage device.
Notice that the flip-flop is edge-triggered: once the clock is high, changing the D input
doesn't change the output. The clock input should actually be a pulse. This pulse is
created with an AND gate and a delayed NOT gate:
Clock
Verilog
In practice, engineers don't have to worry about transistors or gates. Instead, they
specify the high-level behavior of computer chips with a Hardware Description Language (HDL).
How does an HDL description turn into a computer chip? First, synthesis tools convert HDL to
gates and gates to transistors. Then, place and route (PnR) tools calculate where to
physically place the gates on the chip.
In hardware design, the "front-end" involves logic creation using HDLs like Verilog,
and the "back-end" involves transforming this logic into a physical chip layout.
Let's learn an HDL called Verilog.
Verilator is a tool that "verilates" Verilog code to the C++ programming language
for simulation and testing.
todo: click between os
Install Verilator on Mac:
brew install verilator
Install Verilator on Linux:
apt install verilator
Make a file called hello.v and save this module:
module hello;
initial $display ("Hello World!");
endmodule
Make a file called sim_main.cpp and add this C++ code:
#include "Vhello.h"
#include "verilated.h"
int main(int argc, char **argv, char **env)
{
Verilated::commandArgs(argc, argv);
Vhello *top = new Vhello;
top->eval();
delete top;
return 0;
}
Verilate the module to an executable:
verilator -Wall --cc hello.v --exe --build -j 0 sim_main.cpp
Run the test:
./obj_dir/Vhello
If the executable prints Hello World! it's working.
Blinking an LED
The structure of a Verilog design is as follows:
module [design_name] ( [ports] );
[input_ports]
[output_ports]
[other_signals]
[other_module_instantiations_if_required]
[behavioral_code_for_this_module]
endmoduleRefer to this cheat sheet
for an overview of the Verilog syntax.
Here's a Verilog module that blinks an LED:
module led_ba(
input clk,
output reg led
);
reg [31:0]count;
always @(posedge clk) begin
if(count == 99999999) begin //Time is up
count <= 0; //Reset count register
led <= ~led; //Toggle led (in each second)
end else begin
count <= count + 1; //Counts 100MHz clock
end
end
endmodule
Building a UART
A Universal Asynchronous Receiver-Transmitter (UART) is an IC that sends serialized data
(binary) between computer components.
Memory-Mapped Input-Output (MMIO) and Port-Mapped Input-Output (PMIO) are two ways of sending
data between computer components.
Processor
Coding an Assembler
Assemblers compile assembly language into machine code (binary, 0s and 1s). The assembly and
machine code are specific to a processor's Instruction Set Architecture (ISA).

"RISC architecture is going to change everything."
- Angelina Jolie, Hackers (1995)
There are two main kinds of instruction sets: RISC and CISC.
Intel produces the x86 CISC instruction set and manufactures x86 processors. The ARM company
licenses ARM, a RISC ISA, to other companies for chip manufactures. RISC-V is a newer,
open-source RISC ISA; anyone can design and build RISC-V processors without having to pay for
a license.
Check out the RISC-V specifications
and skim through them. These are the 32-bit instructions for the RISC-V RV32I instruction set:
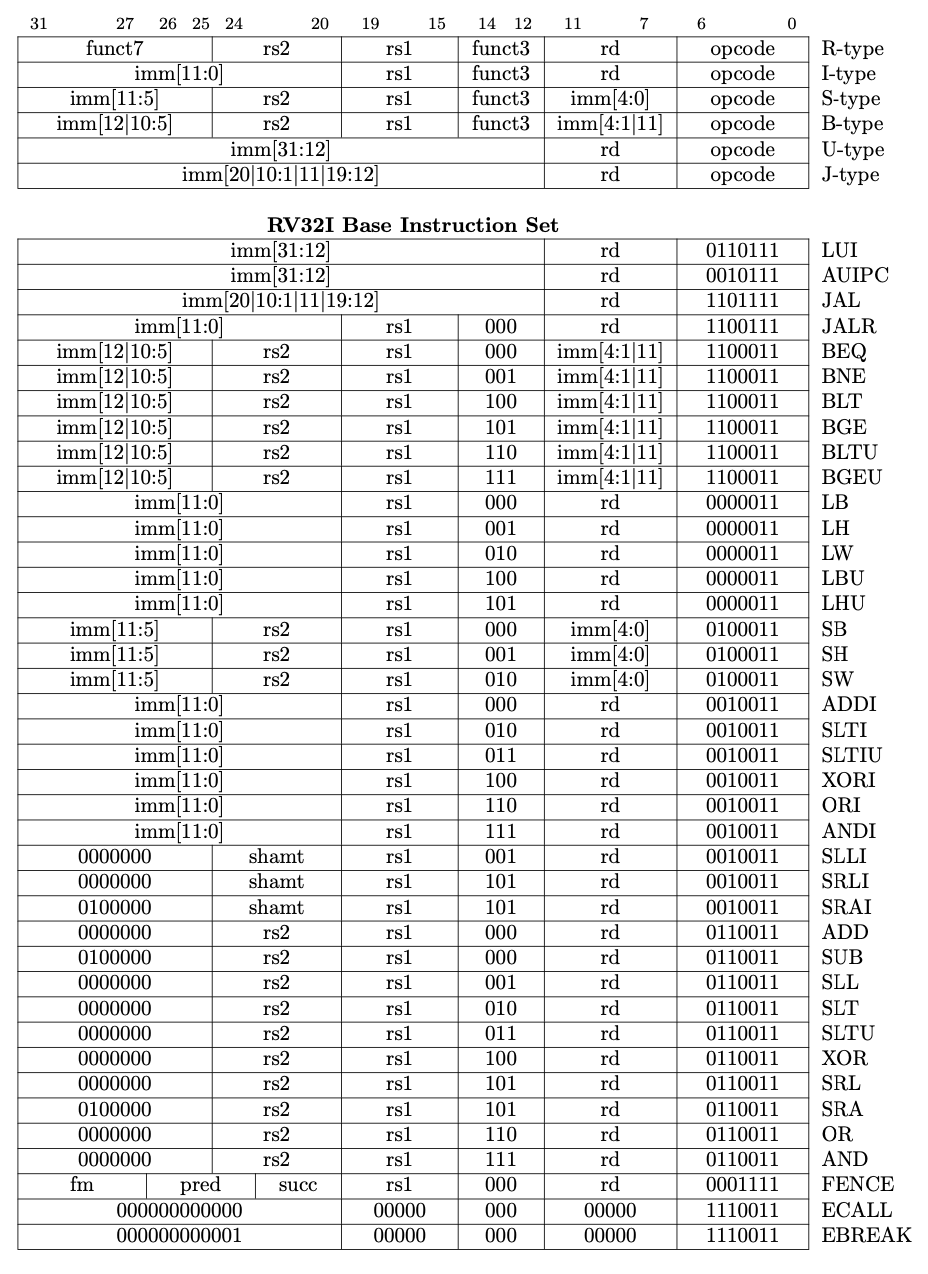
Since this is 32-bit RISC-V, each instruction is 32 bits long.
RISC-V also has 32 8-bit registers:
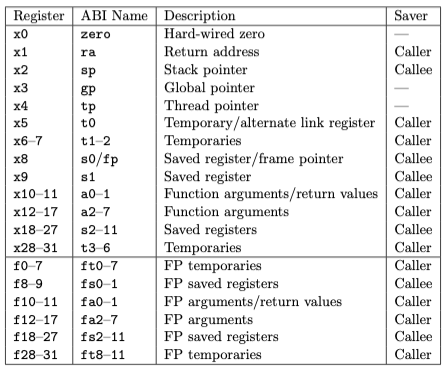
Before we code the assembler, let's assemble some example instructions by hand.
addi sp, sp, -4
sw a0, 0(sp)
Locate ADDI (add immediate) and SW (store word) in the instruction set table:


Note: ADDI is an I-type instruction, and SW is an S-type instruction.
ADDI instruction syntax:
addi rd, rs1, imm
rd is register destination, rs1 is register source 1, and imm is an immediate value.
What is the ADDI doing? It adds -4 (subtracting 4) to rs1, which in our case is sp (the stack
pointer register). The result is then stored in rd, which is also sp. Concisely, the
instruction decrements the stack pointer by 4.
SW instruction syntax:
sw rs2, offset(rs1)
rs1 is register source 1, rs2 is register source 2, and offset is a 12-bit immediate offset
value.
What is the SW doing? The store word instruction takes the word stored in a0 (a general
purpose register), and writes it to memory at the address stored in the stack pointer.
Together, the two instructions decrement the stack pointer and store the value of the a0
register on the stack. They push a value onto the stack.
What do the instructions look like in binary?

Since sp is the x2 register, sp is be encoded as 2 → 00010.
Let's write a RISC-V assembler for the RV32I instruction set in the Zig programming language
. Use these exercises
to learn Zig.
Download Zig from https://ziglang.org/download/ and add it to your path.
Create a new Zig project for the assembler:
mkdir assembler && cd assembler && zig init-exe
Add the starter code for the assembler to src/main.zig:
const std = @import("std");
const print = std.debug.print;
const Instruction = union(enum) {
Addi: struct { rd: u8, rs1: u8, imm: i12 },
Sw: struct { rs1: u8, rs2: u8, offset: i12 },
fn encode(self: *const Instruction) u32 {
switch (self.*) {
.Addi => {
return 0b0;
},
.Sw => {
return 0b0;
},
}
}
};
fn splitStringIntoLines(allocator: *const std.mem.Allocator, input: []const u8) ![][]const u8 {
var lines = std.ArrayList([]const u8).init(allocator.*);
defer lines.deinit();
var tokenizer = std.mem.tokenize(u8, input, "\n");
while (tokenizer.next()) |line| {
try lines.append(line);
}
return lines.toOwnedSlice();
}
pub fn splitStringByWhitespace(allocator: *const std.mem.Allocator, input: []const u8) ![][]const u8 {
var tokens = std.ArrayList([]const u8).init(allocator.*);
defer tokens.deinit();
var tokenizer = std.mem.tokenize(u8, input, " \t\n\r");
while (tokenizer.next()) |token| {
try tokens.append(token);
}
return tokens.toOwnedSlice();
}
fn assemble(allocator: *const std.mem.Allocator, source: []const u8) !std.ArrayList(u32) {
const lines = try splitStringIntoLines(allocator, source);
defer allocator.free(lines);
var encoded = std.ArrayList(u32).init(allocator.*);
for (lines) |line| {
const tokens = try splitStringByWhitespace(allocator, line);
defer allocator.free(tokens);
const instruction = try parseInstruction(allocator, tokens);
try encoded.append(instruction.encode());
}
return encoded;
}
fn parseInstruction(allocator: *const std.mem.Allocator, tokens: [][]const u8) !Instruction {
if (std.mem.eql(u8, tokens[0], "addi")) {
const rd = try std.fmt.parseInt(u8, tokens[1][1..], 10);
const rs1 = try std.fmt.parseInt(u8, tokens[2][1..], 10);
const imm = try std.fmt.parseInt(i12, tokens[3], 10);
return Instruction{
.Addi = .{ .rd = rd, .rs1 = rs1, .imm = imm },
};
} else if (std.mem.eql(u8, tokens[0], "sw")) {
const rs2 = try std.fmt.parseInt(u8, tokens[1][1..], 10);
var offset_and_rs1 = std.ArrayList([]const u8).init(allocator.*);
defer offset_and_rs1.deinit();
var it = std.mem.tokenize(u8, tokens[2], "()");
while (it.next()) |token| {
try offset_and_rs1.append(token);
}
const imm = try std.fmt.parseInt(i12, offset_and_rs1.items[0], 10);
const rs1 = try std.fmt.parseInt(u8, offset_and_rs1.items[1][1..], 10);
return Instruction{ .Sw = .{ .rs1 = rs1, .rs2 = rs2, .offset = imm } };
} else {
return error.InvalidInstruction;
}
}
pub fn main() !void {
var arena = std.heap.ArenaAllocator.init(std.heap.page_allocator);
defer arena.deinit();
const allocator = arena.allocator();
const source_code =
\\addi x2 x2 -4
\\sw x10 0(x2)
;
const machine_code = try assemble(&allocator, source_code[0..]);
for (machine_code.items) |code| {
print("{b:0>32}\n", .{code});
}
}
Run the program:
zig build run
The Assembler parses, encodes, and prints each instruction.
The encode function returns the binary encoding of the instruction:
const Instruction = union(enum) {
Addi: struct { rd: u8, rs1: u8, imm: i12 },
Sw: struct { rs1: u8, rs2: u8, offset: i12 },
fn encode(self: *const Instruction) u32 {
switch (self.*) {
.Addi => {
return 0b0;
},
.Sw => {
return 0b0;
},
}
}
};
Right now, it simply returns 0 in binary. Let's implement the encoding.
const Instruction = union(enum) {
Addi: struct { rd: u8, rs1: u8, imm: i12 },
Sw: struct { rs1: u8, rs2: u8, offset: i12 },
fn encode(self: *const Instruction) u32 {
switch (self.*) {
.Addi => |addi| {
const imm = addi.imm & 0xFFF;
return 0b0010011 | (addi.rd << 7) | (0b000 << 12) | (@as(u32, addi.rs1) << 15) | (@as(u32, @as(u12, @bitCast(imm))) << 20);
},
.Sw => |sw| {
const imm11_5 = (@as(u32, @as(u12, @bitCast(sw.offset))) & 0xFE0) << 20; // bits [11:5] of the immediate
const imm4_0 = (@as(u32, @as(u12, @bitCast(sw.offset))) & 0x1F) << 7; // bits [4:0]
return 0b0100011 | imm4_0 | (0b010 << 12) | (@as(u32, sw.rs1) << 15) | (@as(u32, sw.rs2) << 20) | imm11_5;
},
}
}
};
In binary, negative integers are encoded using Two's complement
. In the ADDI, -4 is represented by encoding 4, flipping all the bits, and adding 1.
0000000000000100 → 1111111111111011 → 1111111111111100
After we cast to a u32, we perform a bit-wise AND (&) with 0xFFF (12 1s) in order to get 12
bits.
1111111111111100 → 00000000000000001111111111111100 →
00000000000000000000111111111100
Once we have our 12-bit imm properly represented in 32 bits, we assemble the encoded
instructions using a bit-wise OR (|) and Zig's right-shift operator >>:
0b0010011 | ((*rd as u32) << 7) | (0b000 << 12) | ((*rs1 as u32) << 15) | (imm_as_u32 << 20)
Before implementing the rest of the instructions, change the Instruction enum to pattern match
by the instruction type, since each instruction type is encoded similarly.
const Instruction = union(enum) {
Rtype: struct {
instruction: RTypeInstruction,
rd: u8,
rs1: u8,
rs2: u8,
},
Itype: struct {
instruction: ITypeInstruction,
rd: u8,
rs1: u8,
imm: i12,
},
Stype: struct {
instruction: STypeInstruction,
rs1: u8,
rs2: u8,
imm: i12,
},
Btype: struct {
instruction: BTypeInstruction,
rs1: u8,
rs2: u8,
imm: i12,
},
Utype: struct {
instruction: UTypeInstruction,
rd: u8,
imm: i32,
},
Jtype: struct {
instruction: JTypeInstruction,
rd: u8,
imm: i32,
},
fn encode(self: *const Instruction) !u32 {
return switch (self.*) {
.Itype => |itype| blk: {
break :blk switch (itype.instruction) {
.Addi => iblk: {
const imm = itype.imm & 0xFFF;
break :iblk 0b0010011 | (itype.rd << 7) | (0b000 << 12) | (@as(u32, itype.rs1) << 15) | (@as(u32, @as(u12, @bitCast(imm))) << 20);
},
else => {
return error.NotImplemented;
},
};
},
.Stype => |stype| blk: {
break :blk switch (stype.instruction) {
.Sw => iblk: {
const imm11_5 = (@as(u32, @as(u12, @bitCast(stype.imm))) & 0xFE0) << 20; // bits [11:5] of the immediate
const imm4_0 = (@as(u32, @as(u12, @bitCast(stype.imm))) & 0x1F) << 7; // bits [4:0]
break :iblk 0b0100011 | imm4_0 | (0b010 << 12) | (@as(u32, stype.rs1) << 15) | (@as(u32, stype.rs2) << 20) | imm11_5;
},
else => {
return error.NotImplemented;
},
};
},
else => {
return error.NotImplemented;
},
};
}
};
Give each instruction type its own enum:
const RTypeInstruction = enum {
Add,
Sub,
Sll,
Slt,
Sltu,
Xor,
Srl,
Sra,
Or,
And,
};
const ITypeInstruction = enum {
Addi,
Slti,
Sltiu,
Xori,
Ori,
Andi,
Slli,
Srli,
Srai,
Lb,
Lh,
Lw,
Lbu,
Lhu,
Jalr,
};
const STypeInstruction = enum {
Sb,
Sh,
Sw,
};
const BTypeInstruction = enum {
Beq,
Bne,
Blt,
Bge,
Bltu,
Bgeu,
};
const UTypeInstruction = enum {
Lui,
Auipc,
};
const JTypeInstruction = enum {
Jal,
};
Notice that the starter code uses register numbers (x0-x32) instead of ABI names. To support
both, add createRegMap and parseRegister functions to the Assembler implementation:
fn createRegMap(allocator: *const std.mem.Allocator) !std.StringHashMap(u8) {
const reg_names = [_][]const u8{
"zero", "ra", "sp", "gp", "tp", "t0", "t1", "t2", "s0", "s1", "a0", "a1", "a2", "a3",
"a4", "a5", "a6", "a7", "s2", "s3", "s4", "s5", "s6", "s7", "s8", "s9", "s10", "s11",
"t3", "t4", "t5", "t6",
};
var map = std.StringHashMap(u8).init(allocator.*);
for (reg_names, 0..) |name, index| {
try map.put(name, @as(u8, @intCast(index)));
}
try map.put("fp", 8);
return map;
}
fn parseRegister(reg: []const u8, reg_map: *const std.StringHashMap(u8)) !u8 {
if (reg[0] == 'x') {
return try std.fmt.parseInt(u8, reg[1..], 10);
} else {
return reg_map.get(reg).?;
}
}
Use the parseRegister function to parse the registers:
const rd = try parseRegister(tokens[1], ®_map);
Add these tests to the bottom of main.zig:
test "add" {
const machine_code = try assemble(&std.testing.allocator, "add ra sp gp");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x3100B3), machine_code.items[0]);
}
test "sub" {
const machine_code = try assemble(&std.testing.allocator, "sub tp t0 t1");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x40628233), machine_code.items[0]);
}
test "sll" {
const machine_code = try assemble(&std.testing.allocator, "sll t2 s0 fp");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x8413B3), machine_code.items[0]);
}
test "slt" {
const machine_code = try assemble(&std.testing.allocator, "slt s1 a0 a1");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0xB524B3), machine_code.items[0]);
}
test "sltu" {
const machine_code = try assemble(&std.testing.allocator, "sltu a2 a3 a4");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0xE6B633), machine_code.items[0]);
}
test "xor" {
const machine_code = try assemble(&std.testing.allocator, "xor a5 a6 a7");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x11847B3), machine_code.items[0]);
}
test "srl" {
const machine_code = try assemble(&std.testing.allocator, "srl s2 s3 s4");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x149D933), machine_code.items[0]);
}
test "sra" {
const machine_code = try assemble(&std.testing.allocator, "sra s5 s6 s7");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x417B5AB3), machine_code.items[0]);
}
test "or" {
const machine_code = try assemble(&std.testing.allocator, "or s8 s9 s10");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x1ACEC33), machine_code.items[0]);
}
test "and" {
const machine_code = try assemble(&std.testing.allocator, "and t3 t4 t5");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x1EEFE33), machine_code.items[0]);
}
test "addi" {
const machine_code = try assemble(&std.testing.allocator, "addi t6 ra 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x308F93), machine_code.items[0]);
}
test "slti" {
const machine_code = try assemble(&std.testing.allocator, "slti sp sp 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x312113), machine_code.items[0]);
}
test "sltiu" {
const machine_code = try assemble(&std.testing.allocator, "sltiu a0 a0 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x353513), machine_code.items[0]);
}
test "xori" {
const machine_code = try assemble(&std.testing.allocator, "xori a1 a1 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x35C593), machine_code.items[0]);
}
test "ori" {
const machine_code = try assemble(&std.testing.allocator, "ori a2 a2 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x366613), machine_code.items[0]);
}
test "andi" {
const machine_code = try assemble(&std.testing.allocator, "andi a3 a3 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x36F693), machine_code.items[0]);
}
test "slli" {
const machine_code = try assemble(&std.testing.allocator, "slli a4 a4 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x371713), machine_code.items[0]);
}
test "srai" {
const machine_code = try assemble(&std.testing.allocator, "srai a6 a6 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x40385813), machine_code.items[0]);
}
test "lb" {
const machine_code = try assemble(&std.testing.allocator, "lb a7 a7 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x388883), machine_code.items[0]);
}
test "lh" {
const machine_code = try assemble(&std.testing.allocator, "lh s0 s0 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x341403), machine_code.items[0]);
}
test "lw" {
const machine_code = try assemble(&std.testing.allocator, "lw s1 s1 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x34A483), machine_code.items[0]);
}
test "lbu" {
const machine_code = try assemble(&std.testing.allocator, "lbu s2 s2 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x394903), machine_code.items[0]);
}
test "lhu" {
const machine_code = try assemble(&std.testing.allocator, "lhu s3 4(s3)");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x49d983), machine_code.items[0]);
}
test "sb" {
const machine_code = try assemble(&std.testing.allocator, "sb s4 0(s4)");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x14a0023), machine_code.items[0]);
}
test "sh" {
const machine_code = try assemble(&std.testing.allocator, "sh s5 2(s5)");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x15a9123), machine_code.items[0]);
}
test "sw" {
const machine_code = try assemble(&std.testing.allocator, "sw s6 3(s6)");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x16b21a3), machine_code.items[0]);
}
test "beq" {
const machine_code = try assemble(&std.testing.allocator, "beq s7 s7 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x17b8163), machine_code.items[0]);
}
test "bne" {
const machine_code = try assemble(&std.testing.allocator, "bne t0 t0 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x529163), machine_code.items[0]);
}
test "blt" {
const machine_code = try assemble(&std.testing.allocator, "blt t1 t1 4");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x634263), machine_code.items[0]);
}
test "bge" {
const machine_code = try assemble(&std.testing.allocator, "bge t2 t2 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x73d163), machine_code.items[0]);
}
test "bltu" {
const machine_code = try assemble(&std.testing.allocator, "bltu t3 t3 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x1ce6163), machine_code.items[0]);
}
test "bgeu" {
const machine_code = try assemble(&std.testing.allocator, "bgeu t4 t4 2");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x1def163), machine_code.items[0]);
}
test "lui" {
const machine_code = try assemble(&std.testing.allocator, "lui t5 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x3f37), machine_code.items[0]);
}
test "auipc" {
const machine_code = try assemble(&std.testing.allocator, "auipc t6 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x3f97), machine_code.items[0]);
}
test "jal" {
const machine_code = try assemble(&std.testing.allocator, "jal ra 0");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0xef), machine_code.items[0]);
}
test "jalr" {
const machine_code = try assemble(&std.testing.allocator, "jalr sp 3(sp)");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x310167), machine_code.items[0]);
}
Test the assembler:
zig build test
This should be enough information to code the rest of the assembler on your own.
Here's the finished assembler:
const std = @import("std");
const print = std.debug.print;
const RTypeInstruction = enum {
Add,
Sub,
Sll,
Slt,
Sltu,
Xor,
Srl,
Sra,
Or,
And,
};
const ITypeInstruction = enum {
Addi,
Slti,
Sltiu,
Xori,
Ori,
Andi,
Slli,
Srli,
Srai,
Lb,
Lh,
Lw,
Lbu,
Lhu,
Jalr,
};
const STypeInstruction = enum {
Sb,
Sh,
Sw,
};
const BTypeInstruction = enum {
Beq,
Bne,
Blt,
Bge,
Bltu,
Bgeu,
};
const UTypeInstruction = enum {
Lui,
Auipc,
};
const JTypeInstruction = enum {
Jal,
};
const Instruction = union(enum) {
RType: struct {
instruction: RTypeInstruction,
rd: u8,
rs1: u8,
rs2: u8,
},
IType: struct {
instruction: ITypeInstruction,
rd: u8,
rs1: u8,
imm: i12,
},
SType: struct {
instruction: STypeInstruction,
rs1: u8,
rs2: u8,
imm: i12,
},
BType: struct {
instruction: BTypeInstruction,
rs1: u8,
rs2: u8,
imm: i12,
},
UType: struct {
instruction: UTypeInstruction,
rd: u8,
imm: i32,
},
JType: struct {
instruction: JTypeInstruction,
rd: u8,
imm: i32,
},
fn encode(self: *const Instruction) !u32 {
switch (self.*) {
.RType => |rtype| {
const opcode: u32 = switch (rtype.instruction) {
.Add => 0b0110011,
.Sub => 0b0110011,
.Sll => 0b0110011,
.Slt => 0b0110011,
.Sltu => 0b0110011,
.Xor => 0b0110011,
.Srl => 0b0110011,
.Sra => 0b0110011,
.Or => 0b0110011,
.And => 0b0110011,
};
const funct3: u32 = switch (rtype.instruction) {
.Add => 0b000,
.Sub => 0b000,
.Sll => 0b001,
.Slt => 0b010,
.Sltu => 0b011,
.Xor => 0b100,
.Srl => 0b101,
.Sra => 0b101,
.Or => 0b110,
.And => 0b111,
};
const funct7: u32 = switch (rtype.instruction) {
.Add => 0b0000000,
.Sub => 0b0100000,
.Sll => 0b0000000,
.Slt => 0b0000000,
.Sltu => 0b0000000,
.Xor => 0b0000000,
.Srl => 0b0000000,
.Sra => 0b0100000,
.Or => 0b0000000,
.And => 0b0000000,
};
return opcode | (@as(u32, rtype.rd) << 7) | (funct3 << 12) | (@as(u32, rtype.rs1) << 15) | (@as(u32, rtype.rs2) << 20) | (funct7 << 25);
},
.IType => |itype| {
const imm_as_u32: u32 = switch (itype.instruction) {
.Slli => @as(u32, @as(u12, @bitCast(itype.imm))) & 0x1F,
.Srli => @as(u32, @as(u12, @bitCast(itype.imm))) & 0x1F,
.Srai => (0b0100000 << 5) | (@as(u32, @as(u12, @bitCast(itype.imm))) & 0x1F),
else => @as(u32, @as(u12, @bitCast(itype.imm))) & 0xFFF,
};
const opcode: u32 = switch (itype.instruction) {
.Addi => 0b0010011,
.Slti => 0b0010011,
.Sltiu => 0b0010011,
.Xori => 0b0010011,
.Ori => 0b0010011,
.Andi => 0b0010011,
.Slli => 0b0010011,
.Srli => 0b0010011,
.Srai => 0b0010011,
.Lb => 0b0000011,
.Lh => 0b0000011,
.Lw => 0b0000011,
.Lbu => 0b0000011,
.Lhu => 0b0000011,
.Jalr => 0b1100111,
};
const funct3: u32 = switch (itype.instruction) {
.Addi => 0b000,
.Slti => 0b010,
.Sltiu => 0b011,
.Xori => 0b100,
.Ori => 0b110,
.Andi => 0b111,
.Slli => 0b001,
.Srli => 0b101,
.Srai => 0b101,
.Lb => 0b000,
.Lh => 0b001,
.Lw => 0b010,
.Lbu => 0b100,
.Lhu => 0b101,
.Jalr => 0b000,
};
return opcode | (@as(u32, itype.rd) << 7) | (funct3 << 12) | (@as(u32, itype.rs1) << 15) | (imm_as_u32 << 20);
},
.SType => |stype| {
const imm11_5 = (@as(u32, @as(u12, @bitCast(stype.imm))) & 0xFE0) << 20; // bits [11:5] of the immediate
const imm4_0 = (@as(u32, @as(u12, @bitCast(stype.imm))) & 0x1F) << 7; // bits [4:0]
const opcode: u32 = switch (stype.instruction) {
.Sb => 0b0100011,
.Sh => 0b0100011,
.Sw => 0b0100011,
};
const funct3: u32 = switch (stype.instruction) {
.Sb => 0b000,
.Sh => 0b001,
.Sw => 0b010,
};
return opcode | imm4_0 | (funct3 << 12) | (@as(u32, stype.rs1) << 15) | (@as(u32, stype.rs2) << 20) | imm11_5;
},
.BType => |btype| {
const imm11 = (@as(u32, @as(u12, @bitCast(btype.imm))) & 0x800) << 20; // bit 11 of the immediate
const imm4_1 = (@as(u32, @as(u12, @bitCast(btype.imm))) & 0x1E) << 7; // bits [4:1] of the immediate
const imm10_5 = (@as(u32, @as(u12, @bitCast(btype.imm))) & 0x7E0) << 20; // bits [10:5] of the immediate
const imm12 = (@as(u32, @as(u12, @bitCast(btype.imm))) & 0x1000) << 19; // bit 12 of the immediate
const opcode: u32 = switch (btype.instruction) {
.Beq => 0b1100011,
.Bne => 0b1100011,
.Blt => 0b1100011,
.Bge => 0b1100011,
.Bltu => 0b1100011,
.Bgeu => 0b1100011,
};
const funct3: u32 = switch (btype.instruction) {
.Beq => 0b000,
.Bne => 0b001,
.Blt => 0b100,
.Bge => 0b101,
.Bltu => 0b110,
.Bgeu => 0b111,
};
return opcode | imm11 | imm4_1 | (funct3 << 12) | (@as(u32, btype.rs1) << 15) | (@as(u32, btype.rs2) << 20) | imm10_5 | imm12;
},
.UType => |utype| {
const imm31_12 = @as(u32, @bitCast(utype.imm)) << 12 & 0xFFFFF000; // bits [31:12] of the immediate
const opcode: u32 = switch (utype.instruction) {
.Lui => 0b0110111,
.Auipc => 0b0010111,
};
return opcode | (@as(u32, utype.rd) << 7) | imm31_12;
},
.JType => |jtype| {
const imm20 = (@as(u32, @bitCast(jtype.imm)) & 0x80000) << 11; // bit 20 of the immediate
const imm10_1 = (@as(u32, @bitCast(jtype.imm)) & 0x7FE) << 20; // bits [10:1] of the immediate
const imm11 = (@as(u32, @bitCast(jtype.imm)) & 0x100000) >> 9; // bit 11 of the immediate
const imm19_12 = (@as(u32, @bitCast(jtype.imm)) & 0xFF000) << 1; // bits [19:12] of the immediate
const opcode: u32 = 0b1101111;
return opcode | (@as(u32, jtype.rd) << 7) | imm19_12 | imm11 | imm10_1 | imm20;
},
}
}
};
fn splitStringIntoLines(allocator: *const std.mem.Allocator, input: []const u8) ![][]const u8 {
var lines = std.ArrayList([]const u8).init(allocator.*);
defer lines.deinit();
var tokenizer = std.mem.tokenize(u8, input, "\n");
while (tokenizer.next()) |line| {
try lines.append(line);
}
return lines.toOwnedSlice();
}
pub fn splitStringByWhitespace(allocator: *const std.mem.Allocator, input: []const u8) ![][]const u8 {
var tokens = std.ArrayList([]const u8).init(allocator.*);
defer tokens.deinit();
var tokenizer = std.mem.tokenize(u8, input, " \t\n\r");
while (tokenizer.next()) |token| {
try tokens.append(token);
}
return tokens.toOwnedSlice();
}
fn assemble(allocator: *const std.mem.Allocator, source: []const u8) !std.ArrayList(u32) {
const lines = try splitStringIntoLines(allocator, source);
defer allocator.free(lines);
var encoded = std.ArrayList(u32).init(allocator.*);
for (lines) |line| {
const tokens = try splitStringByWhitespace(allocator, line);
defer allocator.free(tokens);
const instruction = try parseInstruction(allocator, tokens);
try encoded.append(try instruction.encode());
}
return encoded;
}
fn createRegMap(allocator: *const std.mem.Allocator) !std.StringHashMap(u8) {
const reg_names = [_][]const u8{
"zero", "ra", "sp", "gp", "tp", "t0", "t1", "t2", "s0", "s1", "a0", "a1", "a2", "a3",
"a4", "a5", "a6", "a7", "s2", "s3", "s4", "s5", "s6", "s7", "s8", "s9", "s10", "s11",
"t3", "t4", "t5", "t6",
};
var map = std.StringHashMap(u8).init(allocator.*);
for (reg_names, 0..) |name, index| {
try map.put(name, @as(u8, @intCast(index)));
}
try map.put("fp", 8);
return map;
}
fn parseRegister(reg: []const u8, reg_map: *const std.StringHashMap(u8)) !u8 {
if (reg[0] == 'x') {
return try std.fmt.parseInt(u8, reg[1..], 10);
} else {
return reg_map.get(reg).?;
}
}
fn matchesAny(input: []const u8, candidates: []const []const u8) bool {
for (candidates) |candidate| {
if (std.mem.eql(u8, input, candidate)) {
return true;
}
}
return false;
}
fn getRTypeInstruction(instruction: []const u8) !RTypeInstruction {
if (std.mem.eql(u8, instruction, "add")) return RTypeInstruction.Add;
if (std.mem.eql(u8, instruction, "sub")) return RTypeInstruction.Sub;
if (std.mem.eql(u8, instruction, "sll")) return RTypeInstruction.Sll;
if (std.mem.eql(u8, instruction, "slt")) return RTypeInstruction.Slt;
if (std.mem.eql(u8, instruction, "sltu")) return RTypeInstruction.Sltu;
if (std.mem.eql(u8, instruction, "xor")) return RTypeInstruction.Xor;
if (std.mem.eql(u8, instruction, "srl")) return RTypeInstruction.Srl;
if (std.mem.eql(u8, instruction, "sra")) return RTypeInstruction.Sra;
if (std.mem.eql(u8, instruction, "or")) return RTypeInstruction.Or;
if (std.mem.eql(u8, instruction, "and")) return RTypeInstruction.And;
unreachable;
}
fn getITypeInstruction(instruction: []const u8) !ITypeInstruction {
if (std.mem.eql(u8, instruction, "addi")) return ITypeInstruction.Addi;
if (std.mem.eql(u8, instruction, "slti")) return ITypeInstruction.Slti;
if (std.mem.eql(u8, instruction, "sltiu")) return ITypeInstruction.Sltiu;
if (std.mem.eql(u8, instruction, "xori")) return ITypeInstruction.Xori;
if (std.mem.eql(u8, instruction, "ori")) return ITypeInstruction.Ori;
if (std.mem.eql(u8, instruction, "andi")) return ITypeInstruction.Andi;
if (std.mem.eql(u8, instruction, "slli")) return ITypeInstruction.Slli;
if (std.mem.eql(u8, instruction, "srli")) return ITypeInstruction.Srli;
if (std.mem.eql(u8, instruction, "srai")) return ITypeInstruction.Srai;
if (std.mem.eql(u8, instruction, "lb")) return ITypeInstruction.Lb;
if (std.mem.eql(u8, instruction, "lh")) return ITypeInstruction.Lh;
if (std.mem.eql(u8, instruction, "lw")) return ITypeInstruction.Lw;
if (std.mem.eql(u8, instruction, "lbu")) return ITypeInstruction.Lbu;
if (std.mem.eql(u8, instruction, "lhu")) return ITypeInstruction.Lhu;
if (std.mem.eql(u8, instruction, "jalr")) return ITypeInstruction.Jalr;
unreachable;
}
fn getSTypeInstruction(instruction: []const u8) !STypeInstruction {
if (std.mem.eql(u8, instruction, "sb")) return STypeInstruction.Sb;
if (std.mem.eql(u8, instruction, "sh")) return STypeInstruction.Sh;
if (std.mem.eql(u8, instruction, "sw")) return STypeInstruction.Sw;
unreachable;
}
fn getBTypeInstruction(instruction: []const u8) !BTypeInstruction {
if (std.mem.eql(u8, instruction, "beq")) return BTypeInstruction.Beq;
if (std.mem.eql(u8, instruction, "bne")) return BTypeInstruction.Bne;
if (std.mem.eql(u8, instruction, "blt")) return BTypeInstruction.Blt;
if (std.mem.eql(u8, instruction, "bge")) return BTypeInstruction.Bge;
if (std.mem.eql(u8, instruction, "bltu")) return BTypeInstruction.Bltu;
if (std.mem.eql(u8, instruction, "bgeu")) return BTypeInstruction.Bgeu;
unreachable;
}
fn getUTypeInstruction(instruction: []const u8) !UTypeInstruction {
if (std.mem.eql(u8, instruction, "lui")) return UTypeInstruction.Lui;
if (std.mem.eql(u8, instruction, "auipc")) return UTypeInstruction.Auipc;
unreachable;
}
fn parseInstruction(allocator: *const std.mem.Allocator, tokens: [][]const u8) !Instruction {
var reg_map = try createRegMap(allocator);
defer reg_map.deinit();
const instruction = tokens[0];
const rtype_instructions = [_][]const u8{ "add", "sub", "sll", "slt", "sltu", "xor", "srl", "sra", "or", "and" };
const itype_instructions = [_][]const u8{ "addi", "slti", "sltiu", "xori", "ori", "andi", "slli", "srli", "srai", "lb", "lh", "lw", "lbu", "lhu", "jalr" };
const stype_instructions = [_][]const u8{ "sb", "sh", "sw" };
const btype_instructions = [_][]const u8{ "beq", "bne", "blt", "bge", "bltu", "bgeu" };
const utype_instructions = [_][]const u8{ "lui", "auipc" };
if (matchesAny(instruction, &rtype_instructions)) {
const rd = try parseRegister(tokens[1], ®_map);
const rs1 = try parseRegister(tokens[2], ®_map);
const rs2 = try parseRegister(tokens[3], ®_map);
const rtype_instruction = try getRTypeInstruction(instruction);
return Instruction{
.RType = .{
.instruction = rtype_instruction,
.rd = rd,
.rs1 = rs1,
.rs2 = rs2,
},
};
} else if (matchesAny(instruction, &itype_instructions)) {
const rd = try parseRegister(tokens[1], ®_map);
var imm: i12 = undefined;
var rs1: u8 = undefined;
if (std.mem.eql(u8, instruction, "jalr") or std.mem.eql(u8, instruction, "lhu")) {
var offset_and_rs1 = std.ArrayList([]const u8).init(allocator.*);
defer offset_and_rs1.deinit();
var it = std.mem.tokenize(u8, tokens[2], "()");
while (it.next()) |token| {
try offset_and_rs1.append(token);
}
imm = try std.fmt.parseInt(i12, offset_and_rs1.items[0], 10);
rs1 = try parseRegister(offset_and_rs1.items[1], ®_map);
} else {
rs1 = try parseRegister(tokens[2], ®_map);
imm = try std.fmt.parseInt(i12, tokens[3], 10);
}
const itype_instruction = try getITypeInstruction(instruction);
return Instruction{
.IType = .{
.instruction = itype_instruction,
.rd = rd,
.rs1 = rs1,
.imm = imm,
},
};
} else if (matchesAny(instruction, &stype_instructions)) {
const rs2 = try parseRegister(tokens[1], ®_map);
var offset_and_rs1 = std.ArrayList([]const u8).init(allocator.*);
defer offset_and_rs1.deinit();
var it = std.mem.tokenize(u8, tokens[2], "()");
while (it.next()) |token| {
try offset_and_rs1.append(token);
}
const imm = try std.fmt.parseInt(i12, offset_and_rs1.items[0], 10);
const rs1 = try parseRegister(offset_and_rs1.items[1], ®_map);
const stype_instruction = try getSTypeInstruction(instruction);
return Instruction{
.SType = .{
.instruction = stype_instruction,
.rs1 = rs1,
.rs2 = rs2,
.imm = imm,
},
};
} else if (matchesAny(instruction, &btype_instructions)) {
const rs1 = try parseRegister(tokens[1], ®_map);
const rs2 = try parseRegister(tokens[2], ®_map);
const imm = try std.fmt.parseInt(i12, tokens[3], 10);
const btype_instruction = try getBTypeInstruction(instruction);
return Instruction{
.BType = .{
.instruction = btype_instruction,
.rs1 = rs1,
.rs2 = rs2,
.imm = imm,
},
};
} else if (matchesAny(instruction, &utype_instructions)) {
const rd = try parseRegister(tokens[1], ®_map);
const imm = try std.fmt.parseInt(i32, tokens[2], 10);
const utype_instruction = try getUTypeInstruction(instruction);
return Instruction{
.UType = .{
.instruction = utype_instruction,
.rd = rd,
.imm = imm,
},
};
} else if (std.mem.eql(u8, instruction, "jal")) {
const rd = try parseRegister(tokens[1], ®_map);
const imm = try std.fmt.parseInt(i32, tokens[2], 10);
return Instruction{
.JType = .{
.instruction = JTypeInstruction.Jal,
.rd = rd,
.imm = imm,
},
};
}
unreachable;
}
pub fn main() !void {
var arena = std.heap.ArenaAllocator.init(std.heap.page_allocator);
arena.deinit();
const allocator = arena.allocator();
const source_code =
\\addi x2 x2 -4
\\sw x10 0(x2)
;
const machine_code = try assemble(&allocator, source_code[0..]);
defer machine_code.deinit();
for (machine_code.items) |code| {
print("{b:0>32}\n", .{code});
}
}
test "add" {
const machine_code = try assemble(&std.testing.allocator, "add ra sp gp");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x3100B3), machine_code.items[0]);
}
test "sub" {
const machine_code = try assemble(&std.testing.allocator, "sub tp t0 t1");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x40628233), machine_code.items[0]);
}
test "sll" {
const machine_code = try assemble(&std.testing.allocator, "sll t2 s0 fp");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x8413B3), machine_code.items[0]);
}
test "slt" {
const machine_code = try assemble(&std.testing.allocator, "slt s1 a0 a1");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0xB524B3), machine_code.items[0]);
}
test "sltu" {
const machine_code = try assemble(&std.testing.allocator, "sltu a2 a3 a4");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0xE6B633), machine_code.items[0]);
}
test "xor" {
const machine_code = try assemble(&std.testing.allocator, "xor a5 a6 a7");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x11847B3), machine_code.items[0]);
}
test "srl" {
const machine_code = try assemble(&std.testing.allocator, "srl s2 s3 s4");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x149D933), machine_code.items[0]);
}
test "sra" {
const machine_code = try assemble(&std.testing.allocator, "sra s5 s6 s7");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x417B5AB3), machine_code.items[0]);
}
test "or" {
const machine_code = try assemble(&std.testing.allocator, "or s8 s9 s10");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x1ACEC33), machine_code.items[0]);
}
test "and" {
const machine_code = try assemble(&std.testing.allocator, "and t3 t4 t5");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x1EEFE33), machine_code.items[0]);
}
test "addi" {
const machine_code = try assemble(&std.testing.allocator, "addi t6 ra 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x308F93), machine_code.items[0]);
}
test "slti" {
const machine_code = try assemble(&std.testing.allocator, "slti sp sp 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x312113), machine_code.items[0]);
}
test "sltiu" {
const machine_code = try assemble(&std.testing.allocator, "sltiu a0 a0 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x353513), machine_code.items[0]);
}
test "xori" {
const machine_code = try assemble(&std.testing.allocator, "xori a1 a1 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x35C593), machine_code.items[0]);
}
test "ori" {
const machine_code = try assemble(&std.testing.allocator, "ori a2 a2 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x366613), machine_code.items[0]);
}
test "andi" {
const machine_code = try assemble(&std.testing.allocator, "andi a3 a3 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x36F693), machine_code.items[0]);
}
test "slli" {
const machine_code = try assemble(&std.testing.allocator, "slli a4 a4 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x371713), machine_code.items[0]);
}
test "srai" {
const machine_code = try assemble(&std.testing.allocator, "srai a6 a6 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x40385813), machine_code.items[0]);
}
test "lb" {
const machine_code = try assemble(&std.testing.allocator, "lb a7 a7 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x388883), machine_code.items[0]);
}
test "lh" {
const machine_code = try assemble(&std.testing.allocator, "lh s0 s0 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x341403), machine_code.items[0]);
}
test "lw" {
const machine_code = try assemble(&std.testing.allocator, "lw s1 s1 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x34A483), machine_code.items[0]);
}
test "lbu" {
const machine_code = try assemble(&std.testing.allocator, "lbu s2 s2 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x394903), machine_code.items[0]);
}
test "lhu" {
const machine_code = try assemble(&std.testing.allocator, "lhu s3 4(s3)");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x49d983), machine_code.items[0]);
}
test "sb" {
const machine_code = try assemble(&std.testing.allocator, "sb s4 0(s4)");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x14a0023), machine_code.items[0]);
}
test "sh" {
const machine_code = try assemble(&std.testing.allocator, "sh s5 2(s5)");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x15a9123), machine_code.items[0]);
}
test "sw" {
const machine_code = try assemble(&std.testing.allocator, "sw s6 3(s6)");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x16b21a3), machine_code.items[0]);
}
test "beq" {
const machine_code = try assemble(&std.testing.allocator, "beq s7 s7 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x17b8163), machine_code.items[0]);
}
test "bne" {
const machine_code = try assemble(&std.testing.allocator, "bne t0 t0 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x529163), machine_code.items[0]);
}
test "blt" {
const machine_code = try assemble(&std.testing.allocator, "blt t1 t1 4");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x634263), machine_code.items[0]);
}
test "bge" {
const machine_code = try assemble(&std.testing.allocator, "bge t2 t2 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x73d163), machine_code.items[0]);
}
test "bltu" {
const machine_code = try assemble(&std.testing.allocator, "bltu t3 t3 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x1ce6163), machine_code.items[0]);
}
test "bgeu" {
const machine_code = try assemble(&std.testing.allocator, "bgeu t4 t4 2");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x1def163), machine_code.items[0]);
}
test "lui" {
const machine_code = try assemble(&std.testing.allocator, "lui t5 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x3f37), machine_code.items[0]);
}
test "auipc" {
const machine_code = try assemble(&std.testing.allocator, "auipc t6 3");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x3f97), machine_code.items[0]);
}
test "jal" {
const machine_code = try assemble(&std.testing.allocator, "jal ra 0");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0xef), machine_code.items[0]);
}
test "jalr" {
const machine_code = try assemble(&std.testing.allocator, "jalr sp 3(sp)");
defer machine_code.deinit();
try std.testing.expectEqual(@as(u32, 0x310167), machine_code.items[0]);
}
Designing a CPU
Now that we can assemble RISC-V instructions, let's design a RISC-V CPU in Verilog to run
the instructions. The processor will have two inputs: the instruction and the clock.
The CPU will consist of the following modules:
- Top Module: This will be the primary module that connects every other sub-module.
- Program Counter (PC): Keeps track of the current instruction to fetch.
- Instruction Memory: Holds our program.
- Decoder: Determines the operation based on the instruction opcode.
- ALU (Arithmetic Logic Unit): Performs arithmetic and logical operations.
- Registers: 32 x 32-bit general-purpose registers.
- Data Memory: SRAM-based data memory for load/store operations.
module Processor (
input [31:0] instruction,
input clk,
output [7:0] R1, R2, R3
);
...
endmodule
Program Counter
module ProgramCounter(
input wire clk, // Clock
input wire rst, // Synchronous reset
input wire enable, // Enable signal to allow increment or load new value
input wire load, // Load new value signal
input wire [31:0] addr, // New address (if load is asserted)
output reg [31:0] pc // Program counter value
);
always @(posedge clk or posedge rst) begin
if (rst) begin
pc <= 32'b0; // Reset PC value to 0 on reset
end else if (enable) begin
if (load) begin
pc <= addr; // Load new address if load is asserted
end else begin
pc <= pc + 32'b1; // Increment PC value
end
end
end
endmoduleInstruction Memory
module InstructionMemory (
input wire [31:0] addr, // Address input
output reg [31:0] instr_out // Fetched instruction output
);
// Define a memory block (just a small example for simplicity)
// Ideally, this would be much larger (e.g., 1MB as previously mentioned).
reg [31:0] memory[0:255]; // Example: 1KB memory (256x32)
always @(addr) begin
// Fetch instruction based on address. Address is divided by 4 (shifted right by 2 bits)
// because each instruction is 4 bytes (32 bits) wide.
instr_out = memory[addr >> 2];
end
initial begin
// Initialize memory with some instructions. This is just a placeholder.
// In a real scenario, the program or compiler output would populate this.
memory[0] = 32'b00100100100100100100100100100100; // Just example data
memory[1] = 32'b00100100100100100100100100100101;
// ... more instructions ...
end
endmoduleDecoder
A decoder is kind of the opposite of the assembler we wrote. It breaks up the 32-bit
instruction into its parts.
module RV32I_Decoder (
input [31:0] instr, // 32-bit instruction input
output reg [6:0] funct7, // funct7 field
output reg [2:0] funct3, // funct3 field
output reg [4:0] opcode, // opcode field
output reg [31:0] imm, // immediate value, sign-extended when necessary
output reg R_type, // Signal indicating R-type instruction
output reg I_type, // Signal indicating I-type instruction
output reg S_type, // Signal indicating S-type instruction
output reg B_type,
output reg U_type,
output reg J_type
);
parameter OPCODE_R = 7'b0110011; // R-type
parameter OPCODE_I = 7'b0010011; // I-type (immediate operations)
parameter OPCODE_LOAD = 7'b0000011; // Load instructions (I-type format)
parameter OPCODE_STORE = 7'b0100011; // Store instructions (S-type format)
parameter OPCODE_BRANCH = 7'b1100011; // Branch instructions (B-type format)
parameter OPCODE_JAL = 7'b1101111; // Jump and link (J-type)
parameter OPCODE_LUI = 7'b0110111; // Load upper immediate (U-type)
parameter OPCODE_AUIPC = 7'b0010111; // Add upper immediate to PC (U-type)
always @* begin
opcode = instr[6:0];
funct3 = instr[14:12];
funct7 = instr[31:25];
// Decode instruction type based on opcode
R_type = (opcode == OPCODE_R);
I_type = (opcode == OPCODE_I) | (opcode == OPCODE_LOAD);
S_type = (opcode == OPCODE_STORE);
B_type = (opcode == OPCODE_BRANCH);
U_type = (opcode == OPCODE_LUI) | (opcode == OPCODE_AUIPC);
J_type = (opcode == OPCODE_JAL);
// Decode immediate value based on instruction type
if (R_type) begin
funct7 = instr[31:25];
rs2 = instr[24:20];
rs1 = instr[19:15];
funct3 = instr[14:12];
rd = instr[11:7];
end else if (I_type) begin
imm = { {20{instr[31]}}, instr[31:20] };
rs2 = instr[24:20];
rs1 = instr[19:15];
funct3 = instr[14:12];
rd = instr[11:7];
end else if (S_type) begin
imm = { {20{instr[31]}}, instr[31:25], instr[11:7] };
rs2 = instr[24:20];
rs1 = instr[19:15];
funct3 = instr[14:12];
end else if (B_type) begin
imm = { {19{instr[31]}}, instr[31], instr[7], instr[30:25], instr[11:8], 1'b0 };
rs2 = instr[24:20];
rs1 = instr[19:15];
funct3 = instr[14:12];
end else if (U_type) begin
imm = { instr[31:12], 12'b0 };
rd = instr[11:7];
end else if (J_type) begin
imm = { {11{instr[31]}}, instr[31], instr[19:12], instr[20], instr[30:21], 1'b0 };
rd = instr[11:7];
end
end
endmodule
ALU
Invalid code snippet: alu.v
Coding a boot ROM
The boot ROM (Read-Only Memory) is the first code a processor runs. It is physically embedded
in the hardware.
.section .text
.globl _start
_start:
# Initialize the UART for communication
call setup_uart
# Pointer to RAM where the received bytes will be stored
li t0, 0x80000000 # Starting address of RAM
read_loop:
# Check if data is available in UART
call uart_data_available
beqz a0, read_loop # If data is not available, loop back
# Read a byte from UART
call uart_read_byte
# Store the byte into RAM
sb a0, 0(t0)
# Move to next RAM address
addi t0, t0, 1
# You might want to have an exit condition, say if a specific byte is received,
# or after a fixed size of bytes.
# For now, it loops indefinitely.
j read_loop
# Setup UART for communication
setup_uart:
# This is platform specific. Set up your UART registers for communication.
# For this example, I'm assuming a simplistic setup.
ret
# Check if data is available on UART
uart_data_available:
# Platform specific. Read the status register of your UART and return in a0.
# Assuming the status register has a non-zero value if data is available.
# 0x40000000 is a placeholder address for UART status register
li t1, 0x40000000
lbu a0, 0(t1)
ret
# Read a byte from UART
uart_read_byte:
# Platform specific. Read a byte from the UART data register.
# Assuming 0x40000004 is the data register address.
li t1, 0x40000004
lbu a0, 0(t1)
retCompiler
Coding a C Compiler
A compiler translates code written in a programming language to assembly language. Let's
build a C compiler to translate C code into assembly language (in our case, RISC-V). If you
want to learn about compilers in more detail, check out the Crafting Interpreters
book.
Our simple compiler will consist of three parts:
- Lexer - code to tokens
- Syntax Parser - tokens to Abstract Syntax Tree (AST)
- Code Generator - AST to RISC-V assembly
For the sake of simplicity, our C-like programming language will only accept ints and
booleans.
Lexer
A lexer reads a code file character-by-character and converts it into tokens. A token is a
lexeme with a token type label.
Make a new Zig project for the compiler:
mkdir compiler && cd compiler && zig init-exe
In the src directory, add a token.zig file:
pub const TokenType = enum {
// Basic symbols
Comma,
Dot,
Plus,
Minus,
Multiply,
Divide,
Modulo,
Lbrace,
Rbrace,
Lparen,
Rparen,
Semicolon,
// Comparators
IsEqual,
NotEqual,
GreaterThan,
GreaterThanEqual,
LessThan,
LessThanEqual,
// Assignment
Assign,
PlusAssign, // +=
MinusAssign, // -=
// Literal values
CharLiteral,
StringLiteral,
IntegerLiteral,
FloatLiteral,
// Boolean and bitwise
And,
Or,
Not,
BitwiseAnd, // &
BitwiseOr, // |
BitwiseXor, // ^
// Data types
IntType,
FloatType,
DoubleType,
CharType,
VoidType,
ShortType,
LongType,
UnsignedType,
StructType,
UnionType,
EnumType,
// Reserved words
While,
For,
If,
Else,
Return,
// Ternary operator
TernaryQuestion, // ?
TernaryColon, // :
// Identifiers
Id,
};
pub const Token = struct {
token_type: TokenType,
lexeme: []const u8,
line: i32,
column: i32,
};
Here's the finished lexer:
const std = @import("std");
const Token = @import("token.zig").Token;
const TokenType = @import("token.zig").TokenType;
pub const Lexer = struct {
buffer: []const u8,
line: u32,
column: u32,
fn readCharacter(self: Lexer) u8 {
_ = self;
// return buffer.readCharacter();
return 'a';
}
fn peekCharacter(self: Lexer) u8 {
_ = self;
return 'a';
}
fn isWhitespace(char: u8) bool {
return char == ' ' or char == '\t' or char == '\n' or char == '\r';
}
fn isDigit(char: u8) bool {
_ = char;
return true;
}
fn isLetter(char: u8) bool {
_ = char;
return true;
}
pub fn nextToken(self: Lexer, allocator: *const std.mem.Allocator) Token {
const char = readCharacter();
self.column += 1;
while (isWhitespace(char) or std.mem.eql(char, '#')) {
if (std.mem.eql(char, '#')) {
while (!std.mem.eql(char, '\n')) {
char = readCharacter();
self.self.column += 1;
}
char = readCharacter();
self.line += 1;
self.column = 0;
continue;
}
if (std.mem.eql(char, '\n')) {
self.line += 1;
self.column = 0;
}
char = readCharacter();
self.column += 1;
}
if (std.mem.eql(char, ',')) {
return Token{ .token_type = TokenType.COMMA, .lexeme = ",", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, '.')) {
return Token{ .token_type = TokenType.DOT, .lexeme = ".", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, '+')) {
return Token{ .token_type = TokenType.PLUS, .lexeme = "+", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, '-')) {
return Token{ .token_type = TokenType.MINUS, .lexeme = "-", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, '*')) {
return Token{ .token_type = TokenType.MULTIPLY, .lexeme = "*", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, '/')) {
return Token{ .token_type = TokenType.DIVIDE, .lexeme = "/", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, '%')) {
return Token{ .token_type = TokenType.MODULO, .lexeme = "%", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, '{')) {
return Token{ .token_type = TokenType.LBRACE, .lexeme = "{", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, '}')) {
return Token{ .token_type = TokenType.RBRACE, .lexeme = "}", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, '(')) {
return Token{ .token_type = TokenType.LPAREN, .lexeme = "(", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, ')')) {
return Token{ .token_type = TokenType.RPAREN, .lexeme = ")", .line = self.line, .column = self.column };
} else if (std.mem.eql(char, '!')) {
char = readCharacter();
self.column += 1;
if (std.mem.eql(char, '=')) {
return Token{ .token_type = TokenType.NOT_EQUAL, .lexeme = "!=", .line = self.line, .column = self.column - 1 };
} else {
// error(String.format("expecting '=', found '%c'", ch), .line = self.line, .column = self.column};
}
} else if (std.mem.eql(char, '=')) {
const next_char = peekCharacter();
if (std.mem.eql(next_char, '=')) {
next_char = readCharacter();
self.column += 1;
return Token{ .token_type = TokenType.EQUAL, .lexeme = "==", .line = self.line, .column = self.column - 1 };
} else {
return Token{ .token_type = TokenType.ASSIGN, .lexeme = "=", .line = self.line, .column = self.column };
}
} else if (std.mem.eql(char, '>')) {
const next_char = peekCharacter();
if (std.mem.eql(next_char, '=')) {
next_char = readCharacter();
self.column += 1;
return Token{ .token_type = TokenType.GREATER_THAN_EQUAL, .lexeme = ">=", .line = self.line, .column = self.column - 1 };
} else {
return Token{ .token_type = TokenType.GREATER_THAN, .lexeme = ">", .line = self.line, .column = self.column };
}
} else if (std.mem.eql(char, '<')) {
const next_char = peekCharacter();
if (std.mem.eql(next_char, '=')) {
next_char = readCharacter();
self.column += 1;
return Token{ .token_type = TokenType.LESS_THAN_EQUAL, .lexeme = "<=", .line = self.line, .column = self.column - 1 };
} else {
return Token{ .token_type = TokenType.LESS_THAN, .lexeme = "<", .line = self.line, .column = self.column };
}
} else if (std.mem.eql(char, '\'')) {
var lexeme = "";
char = readCharacter();
self.column += 1;
lexeme = lexeme ++ char;
if (std.mem.eql(char, '\'')) {
// error("empty character", .line = self.line, .column = self.column-1);
}
if (std.mem.eql(char, '\n')) {
// error("found newline in character", .line = self.line, .column = self.column};
}
}
if (std.mem.eql(char, '\\')) {
char = readCharacter();
char = readCharacter();
self.column += 1;
if (!std.mem.eql(char, '\'')) {
// error(String.format("expecting ' found, '%c'", ch), .line = self.line, .column = self.column};
}
return Token{ .token_type = TokenType.CHAR_VAL, .lexeme = "", .line = self.line, .column = self.column - 3 };
// lexeme, .line = self.line, .column = self.column - 3 };
}
// ch = readCharacter();
// self.column += 1;
// if (!std.mem.eql(char, '\'')) {
// error(String.format("expecting ' found, '%c'", ch), .line = self.line, .column = self.column-1);
// }
// return Token{.token_type = TokenType.CHAR_VAL, .lexeme = lexeme, .line = self.line, .column = self.column-2};
else if (std.mem.eql(char, '"')) {
var lexeme = "";
const str_len = 1;
char = readCharacter();
self.column += 1;
while (!std.mem.eql(char, '"')) {
if (std.mem.eql(char, '\n')) {
// error("found newself.line within string", .line = self.line, .column = self.column};
}
//if (isEOF(char)) {
// error("found end-of-file in string", .line = self.line, .column = self.column-1);
// }
lexeme = lexeme ++ char;
char = readCharacter();
self.column += 1;
str_len += 1;
}
return Token{ .token_type = TokenType.STRING_VAL, .lexeme = lexeme, .line = self.line, .column = self.column - str_len };
} else if (isDigit(char)) {
var lexeme = "" + char;
var num_length = 0;
var isDouble = false;
while (isDigit(peekCharacter()) || std.mem.eql(peekCharacter(), '.')) {
char = readCharacter();
if (std.mem.eql(char, '.')) {
if (isDouble) {}
isDouble = true;
if (!isDigit(peekCharacter())) {}
}
self.column += 1;
lexeme += char;
num_length += 1;
}
if (lexeme.length() > 1) {
if (std.mem.eql(lexeme.charAt(0), '0') and !std.mem.eql(lexeme.charAt(1), '.')) {
// error(String.format("leading zero in '%s'", lexeme), .line = self.line, .column = self.column-num_length);
}
}
if (isDouble) {
return Token{ .token_type = TokenType.DOUBLE_VAL, .lexeme = lexeme, .line = self.line, .column = self.column - num_length };
} else {
return Token{ .token_type = TokenType.INT_VAL, .lexeme = lexeme, .line = self.line, .column = self.column - num_length };
}
} else if (isLetter(char)) {
var reservedWords = std.StringHashMap(TokenType).init(&allocator);
defer reservedWords.deinit();
reservedWords.put("and", TokenType.AND);
reservedWords.put("or", TokenType.OR);
reservedWords.put("not", TokenType.NOT);
reservedWords.put("neg", TokenType.NEG);
reservedWords.put("int", TokenType.INT_TYPE);
reservedWords.put("double", TokenType.DOUBLE_TYPE);
reservedWords.put("char", TokenType.CHAR_TYPE);
reservedWords.put("string", TokenType.STRING_TYPE);
reservedWords.put("bool", TokenType.BOOL_TYPE);
reservedWords.put("true", TokenType.BOOL_VAL);
reservedWords.put("false", TokenType.BOOL_VAL);
reservedWords.put("void", TokenType.VOID_TYPE);
reservedWords.put("var", TokenType.VAR);
reservedWords.put("type", TokenType.TYPE);
reservedWords.put("while", TokenType.WHILE);
reservedWords.put("for", TokenType.FOR);
reservedWords.put("from", TokenType.FROM);
reservedWords.put("upto", TokenType.UPTO);
reservedWords.put("downto", TokenType.DOWNTO);
reservedWords.put("if", TokenType.IF);
reservedWords.put("elif", TokenType.ELIF);
reservedWords.put("else", TokenType.ELSE);
reservedWords.put("fun", TokenType.FUN);
reservedWords.put("new", TokenType.NEW);
reservedWords.put("delete", TokenType.DELETE);
reservedWords.put("return", TokenType.RETURN);
reservedWords.put("nil", TokenType.NIL);
var lexeme = char;
var word_length = 0;
while (isLetter(peekCharacter()) || isDigit(peekCharacter()) || std.mem.eql(peekCharacter(), '_')) {
char = readCharacter();
self.column += 1;
lexeme += char;
word_length += 1;
if (reservedWords.keySet().contains(lexeme) and !isDigit(peekCharacter()) and !isLetter(peekCharacter())) {
return Token{ .token_type = reservedWords.get(lexeme), .lexeme = lexeme, .line = self.line, .column = self.column - word_length };
}
}
return Token{ .token_type = TokenType.ID, .lexeme = lexeme, .line = self.line, .column = self.column - word_length };
// } else if (isEOF(ch)) {
// return Token{ .token_type = TokenType.EOS, .lexeme = "end-of-file", .line = self.line, .column = self.column };
} else {
// error(String.format("invalid symbol '%c'", ch), .line = self.line, .column = self.column};
}
return Token{ .token_type = TokenType.EOS, .lexeme = "end-of-file", .line = self.line, .column = self.column };
}
};
AST Parser
The parser converts tokens to an Abstract Syntax Tree (AST). The AST is built from the
language grammar. A grammar describes the patterns in which tokens appear. This is what the C
grammar looks like:
const Lexer = @import("lexer.zig").Lexer;
const Token = @import("token.zig").Token;
const TokenType = @import("token.zig").TokenType;
const Parser = struct {
lexer: Lexer,
token: Token,
fn parse(self: Parser) void {
self.token = self.lexer.nextToken();
while (!match(TokenType.EOS)) {
if (self.token == TokenType.TYPE) {
self.typedecl();
} else {
self.fundecl();
}
}
self.token = self.lexer.nextToken();
}
fn match(self: Parser, token_type: TokenType) bool {
return self.token.token_type == token_type;
}
fn isPrimitiveType() bool {
return match(TokenType.INT_TYPE) || match(TokenType.DOUBLE_TYPE) ||
match(TokenType.BOOL_TYPE) || match(TokenType.CHAR_TYPE) ||
match(TokenType.STRING_TYPE);
}
fn isPrimitiveValue() bool {
return match(TokenType.INT_VAL) || match(TokenType.DOUBLE_VAL) ||
match(TokenType.BOOL_VAL) || match(TokenType.CHAR_VAL) ||
match(TokenType.STRING_VAL);
}
fn isExpr() bool {
return match(TokenType.NOT) || match(TokenType.LPAREN) ||
match(TokenType.NIL) || match(TokenType.NEW) ||
match(TokenType.ID) || match(TokenType.NEG) ||
match(TokenType.INT_VAL) || match(TokenType.DOUBLE_VAL) ||
match(TokenType.BOOL_VAL) || match(TokenType.CHAR_VAL) ||
match(TokenType.STRING_VAL);
}
fn isOperator() bool {
return match(TokenType.PLUS) || match(TokenType.MINUS) ||
match(TokenType.DIVIDE) || match(TokenType.MULTIPLY) ||
match(TokenType.MODULO) || match(TokenType.AND) ||
match(TokenType.OR) || match(TokenType.EQUAL) ||
match(TokenType.LESS_THAN) || match(TokenType.GRself.eatER_THAN) ||
match(TokenType.LESS_THAN_EQUAL) || match(TokenType.GRself.eatER_THAN_EQUAL) ||
match(TokenType.NOT_EQUAL);
}
//------------------------------------------------------------
// TODO: Recursive Descent Functions
//------------------------------------------------------------
fn tdecl(self: Parser) void {
self.eat(TokenType.TYPE, "expecting type");
self.eat(TokenType.ID, "expecting ID");
self.eat(TokenType.LBRACE, "expecting left brace");
vdecls();
self.eat(TokenType.RBRACE, "expecting right brace");
}
fn vdecls(self: Parser) void {
_ = self;
while (match(TokenType.VAR)) {
vdeclStmt();
}
}
fn fdecl(self: Parser) void {
self.eat(TokenType.FUN, "expecting fun");
if (match(TokenType.VOID_TYPE)) {
self.eat(TokenType.VOID_TYPE, "expecting void");
} else {
dtype();
}
self.eat(TokenType.ID, "expecting id");
self.eat(TokenType.LPAREN, "expecting left paren");
params();
self.eat(TokenType.RPAREN, "expecting right paren");
self.eat(TokenType.LBRACE, "expecting left brace");
stmts();
self.eat(TokenType.RBRACE, "expecting right brace");
}
fn params(self: Parser) void {
if (isPrimitiveType() || match(TokenType.ID)) {
dtype();
self.eat(TokenType.ID, "expecting id");
while (match(TokenType.COMMA)) {
self.eat(TokenType.COMMA, "expecting comma");
dtype();
self.eat(TokenType.ID, "expecting id");
}
}
}
fn dtype(self: Parser) void {
if (match(TokenType.INT_TYPE)) {
self.eat(TokenType.INT_TYPE, "expecting int type");
} else if (match(TokenType.DOUBLE_TYPE)) {
self.eat(TokenType.DOUBLE_TYPE, "expecting double type");
} else if (match(TokenType.BOOL_TYPE)) {
self.eat(TokenType.BOOL_TYPE, "expecting bool type");
} else if (match(TokenType.CHAR_TYPE)) {
self.eat(TokenType.CHAR_TYPE, "expecting char type");
} else if (match(TokenType.STRING_TYPE)) {
self.eat(TokenType.STRING_TYPE, "expecting string type");
} else if (match(TokenType.ID)) {
self.eat(TokenType.ID, "expecting id");
} else {
// error("expecting data type");
}
}
fn stmts(self: Parser) void {
_ = self;
while (!match(TokenType.RBRACE)) {
stmt();
}
}
fn stmt(self: Parser) void {
if (match(TokenType.VAR)) {
vdeclStmt();
} else if (match(TokenType.DELETE)) {
self.eat(TokenType.DELETE, "expecting delete");
self.eat(TokenType.ID, "expecting id");
} else if (match(TokenType.FOR)) {
forStmt();
} else if (match(TokenType.WHILE)) {
whileStmt();
} else if (match(TokenType.RETURN)) {
retStmt();
} else if (match(TokenType.IF)) {
condStmt();
} else if (match(TokenType.ID)) {
self.eat(TokenType.ID, "expecting id");
// call
if (match(TokenType.LPAREN)) {
self.eat(TokenType.LPAREN, "expecting left paren");
args();
self.eat(TokenType.RPAREN, "expecting right paren");
}
// assign
else {
if (match(TokenType.DOT)) {
self.eat(TokenType.DOT, "expecting a dot");
lvalue();
}
self.eat(TokenType.ASSIGN, "expecting '='");
expr();
}
} else {
// error("expecting statement");
}
}
fn vdeclStmt(self: Parser) void {
self.eat(TokenType.VAR, "expecting var");
if (isPrimitiveType()) {
dtype();
}
self.eat(TokenType.ID, "expecting id");
// self.eat an extra id in case of id dtype
if (match(TokenType.ID)) {
self.eat(TokenType.ID, "expecting id");
}
self.eat(TokenType.ASSIGN, "expecting '='");
expr();
}
fn lvalue(self: Parser) void {
self.eat(TokenType.ID, "expecting id");
if (match(TokenType.DOT)) {
self.eat(TokenType.DOT, "expecting a dot");
lvalue();
}
}
fn condStmt(self: Parser) void {
self.eat(TokenType.IF, "expecting if");
expr();
self.eat(TokenType.LBRACE, "expecting left brace");
stmts();
self.eat(TokenType.RBRACE, "expecting right brace");
condt();
}
fn condt(self: Parser) void {
if (match(TokenType.ELIF)) {
self.eat(TokenType.ELIF, "expecting elif");
expr();
self.eat(TokenType.LBRACE, "expecting left brace");
stmts();
self.eat(TokenType.RBRACE, "expecting right brace");
condt();
} else if (match(TokenType.ELSE)) {
self.eat(TokenType.ELSE, "expecting else");
self.eat(TokenType.LBRACE, "expecting left brace");
stmts();
self.eat(TokenType.RBRACE, "expecting right brace");
}
}
fn whileStmt(self: Parser) void {
self.eat(TokenType.WHILE, "expecting while");
expr();
self.eat(TokenType.LBRACE, "expecting left brace");
stmts();
self.eat(TokenType.RBRACE, "expecting right brace");
}
fn forStmt(self: Parser) void {
self.eat(TokenType.FOR, "expecting for");
self.eat(TokenType.ID, "expecting id");
self.eat(TokenType.FROM, "expecting from");
expr();
if (match(TokenType.UPTO)) {
self.eat(TokenType.UPTO, "expecting upto");
} else if (match(TokenType.DOWNTO)) {
self.eat(TokenType.DOWNTO, "expecting downto");
} else {
// error("expecting upto or downto");
}
expr();
self.eat(TokenType.LBRACE, "expecting left brace");
stmts();
self.eat(TokenType.RBRACE, "expecting right brace");
}
fn args(self: Parser) void {
if (isExpr()) {
expr();
while (match(TokenType.COMMA)) {
self.eat(TokenType.COMMA, "expecting comma");
expr();
}
}
}
fn retStmt(self: Parser) void {
self.eat(TokenType.RETURN, "expecting return");
if (isExpr()) {
expr();
}
}
fn expr(self: Parser) void {
if (match(TokenType.NOT)) {
self.eat(TokenType.NOT, "expecting not");
expr();
} else if (match(TokenType.LPAREN)) {
self.eat(TokenType.LPAREN, "expecting left paren");
expr();
self.eat(TokenType.RPAREN, "expecting right paren");
} else {
rvalue();
}
if (isOperator()) {
operator();
expr();
}
}
fn operator(self: Parser) void {
if (isOperator()) {
self.eat(self.token.token_type, "expecting operator");
}
}
fn rvalue(self: Parser) void {
if (match(TokenType.NIL)) {
self.eat(TokenType.NIL, "expecting nil");
} else if (match(TokenType.NEW)) {
self.eat(TokenType.NEW, "expecting new");
self.eat(TokenType.ID, "expecting id");
} else if (match(TokenType.NEG)) {
self.eat(TokenType.NEG, "expecting neg");
expr();
} else if (isPrimitiveValue()) {
pval();
} else if (match(TokenType.ID)) {
self.eat(TokenType.ID, "expecting id");
// idrval
if (match(TokenType.DOT)) {
while (match(TokenType.DOT)) {
self.eat(TokenType.DOT, "expecting dot");
self.eat(TokenType.ID, "expecting id");
}
}
// call expression
else if (match(TokenType.LPAREN)) {
self.eat(TokenType.LPAREN, "expecting left paren");
args();
self.eat(TokenType.RPAREN, "expecting right paren");
}
} else {
// error("expecting right value");
}
}
fn pval(self: Parser) void {
if (match(TokenType.INT_VAL)) {
self.eat(TokenType.INT_VAL, "expecting int val");
} else if (match(TokenType.DOUBLE_VAL)) {
self.eat(TokenType.DOUBLE_VAL, "expecting double val");
} else if (match(TokenType.BOOL_VAL)) {
self.eat(TokenType.BOOL_VAL, "expecting bool val");
} else if (match(TokenType.CHAR_VAL)) {
self.eat(TokenType.CHAR_VAL, "expecting char val");
} else if (match(TokenType.STRING_VAL)) {
self.eat(TokenType.STRING_VAL, "expecting string val");
} else {
// error("expecting primitive value");
}
}
};
Code Generator
The code generator converts our AST into executable RISC-V instructions (which we can pass to
our assembler!).
Building a linker
use std::fs;
// Step 1: Define the intermediate representation
struct Section {
name: String,
content: String,
}
struct ObjectFile {
sections: Vec<Section>,
}
// Simple ELF header and program header structures
const ELF_HEADER: [u8; 64] = [
0x7f, 0x45, 0x4c, 0x46, // ELF magic
0x02, 0x01, 0x01, 0x00, // ... (rest are default values for simplicity)
// ... (remaining bytes are zeros)
];
const PROGRAM_HEADER: [u8; 56] = [
// ... (default values, with a type, offset, vaddr, paddr, filesz, memsz, flags, align)
];
fn main() {
// Step 2: Read and parse the object files
let object_file = read_object_file("input.obj");
// Step 3: Resolve symbols (skipping for this example)
// Step 4 & 5: Generate ELF and combine content
let mut elf_content = ELF_HEADER.to_vec();
elf_content.extend_from_slice(&PROGRAM_HEADER);
for section in object_file.sections {
elf_content.extend(section.content.as_bytes());
}
// Step 6: Write the ELF file
fs::write("output.elf", &elf_content).expect("Failed to write ELF file");
}
fn read_object_file(path: &str) -> ObjectFile {
let content = fs::read_to_string(path).expect("Failed to read object file");
let mut sections = Vec::new();
let mut lines = content.lines();
while let Some(line) = lines.next() {
if line.starts_with(".text") {
sections.push(Section {
name: ".text".to_string(),
content: lines.next().unwrap_or("").to_string(),
});
} else if line.starts_with(".data") {
sections.push(Section {
name: ".data".to_string(),
content: lines.next().unwrap_or("").to_string(),
});
}
}
ObjectFile { sections }
}Memory Allocation
Dynamic memory allocation is when a program is allocated memory at runtime. This video
gives a great overview.
Building an ethernet controller
Top-Level Architecture:
- MAC (Media Access Control)
- Module PHY Interface
- Module Data Path Control FIFOs for Tx (Transmit) and Rx (Receive) Control and Status Registers
Module Frame parser and builder Address Checker (for filtering destination MAC addresses)
Frame CRC Check and Generation
PHY Interface (Physical Layer Interface)
Depending on the chosen PHY chip or standard (e.g., 10BASE-T, 100BASE-TX, 1000BASE-T), this
module handles the signaling and the interface protocol. Many designs use a standard called
MII (Media Independent Interface) or its variants like GMII, RGMII, etc. Data Path Control
Manages the data flow between FIFOs and MAC Handles frame delimiters, inter-frame gaps, etc.
FIFOs Storage for frames during transmission and reception Helps in flow control, especially
if the processing rate is different from the network rate Control and Status Registers For
configuration, control, and status monitoring of the controller. Can be interfaced to via a
bus like Wishbone, AXI, etc. State Machines To handle various processes like frame reception,
transmission, collision detection, etc.
module ethernet_mac (
input clk, reset,
input [7:0] rx_data,
input rx_valid,
output reg [7:0] tx_data,
output reg tx_valid,
// ... other signals as needed
);
// State definitions for a simple state machine
typedef enum {
IDLE, RECEIVE, TRANSMIT
} states_t;
reg [1:0] current_state, next_state;
always @(posedge clk or posedge reset) begin
if (reset) current_state <= IDLE;
else current_state <= next_state;
end
always @(current_state or rx_valid) begin
case(current_state)
IDLE: begin
if (rx_valid) next_state = RECEIVE;
else next_state = IDLE;
end
RECEIVE: begin
// Handle frame reception
next_state = IDLE; // Placeholder
end
TRANSMIT: begin
// Handle frame transmission
next_state = IDLE; // Placeholder
end
endcase
end
// ... Rest of the design, including FIFOs, data processing, etc.
endmoduleWriting a bootloader
const std = @import("std");
extern fn _start() noreturn {
// Initialize hardware, if necessary.
// Load the operating system kernel from a predefined location.
// For simplicity, this part is omitted.
// Jump to the operating system entry point.
// This is typically done by setting the instruction pointer (IP/EIP/RIP) to the kernel's entry point.
unreachable; // The bootloader should never return.
}
// Disable standard library features not applicable to bootloaders.
pub fn panic(msg: []const u8, error_return_trace: ?*std.builtin.StackTrace) noreturn {
// Handle panics, possibly by printing an error message to a screen or serial port.
// In a real bootloader, you'd halt or reset the machine.
while (true) {}
}
Operating System
Building an MMU
Define Requirements: Size of the physical memory Size of the virtual address space Page size
High-Level Block Diagram: Virtual Address (VA) input Translation Lookaside Buffer (TLB) for
caching recent translations Page table stored in memory (simplification) Physical Address (PA)
output
module MMU (
input [31:0] virtual_addr,
input [31:0] page_table_base, // Base address of the page table in memory
input clk, rst,
output reg [31:0] physical_addr
);
// Define page size as 4KB (12 bits offset)
parameter OFFSET_SIZE = 12;
parameter INDEX_SIZE = 32 - OFFSET_SIZE;
reg [INDEX_SIZE-1:0] page_index;
reg [OFFSET_SIZE-1:0] page_offset;
// For simplicity, let's assume the page table entry contains just the base address of the page
// In a real MMU, this would also include flags for protection, presence, etc.
reg [31:0] page_table_entry;
// Simulating page table in memory as an array
// In a real system, you'd access memory to get this info
reg [31:0] page_table [0:2**INDEX_SIZE-1];
always @(posedge clk or posedge rst) begin
if (rst) begin
physical_addr <= 32'b0;
end else begin
page_index = virtual_addr[31:OFFSET_SIZE];
page_offset = virtual_addr[OFFSET_SIZE-1:0];
// Fetch the page table entry from the simulated page table
// In a real system, this would involve a memory read
page_table_entry = page_table[page_index];
// Combine the page table entry (base address of the page) with the offset to get the physical address
physical_addr = {page_table_entry[31:OFFSET_SIZE], page_offset};
end
end
endmoduleCoding an OS
const std = @import("std");
const HashMap = std.AutoHashMap;
const Mutex = std.Thread.Mutex;
const Arc = std.atomic.AtomicRef;
const ProcessId = usize; // Assuming ProcessId is a simple type like usize
const Priority = u32; // Assuming Priority is a simple type like u32
const Message = struct {
// Define your Message struct here
};
const Process = struct {
thread: ?std.Thread.Handle,
sender: ?std.Channel(Message), // Assuming a channel-like mechanism for message passing
parent_pid: ?ProcessId,
};
const ProcessFunction = fn (?std.Channel(Message).Receiver) void;
const ProcessManager = struct {
processes: HashMap(ProcessId, Process),
next_pid: ProcessId,
priority_queue: Arc(Mutex([]ProcessId)),
child_map: HashMap(ProcessId, []ProcessId),
pub fn new(allocator: *std.mem.Allocator) ProcessManager {
return ProcessManager{
.processes = HashMap(ProcessId, Process).init(allocator),
.next_pid = 0,
.priority_queue = Arc.create(Mutex.init([]ProcessId)) catch unreachable,
.child_map = HashMap(ProcessId, []ProcessId).init(allocator),
};
},
pub fn fork(self: *ProcessManager, parent_pid: ?ProcessId, function: ProcessFunction, priority: Priority) ProcessId {
const pid = self.next_pid;
self.next_pid += 1;
// Rest of the process creation logic...
if (parent_pid) |parent| {
// Handle child mapping
if (!self.child_map.contains(parent)) {
self.child_map.put(parent, &[_]ProcessId{}) catch unreachable;
}
self.child_map.get(parent).?.append(pid) catch unreachable;
}
// Initialize and start the thread here...
self.processes.put(pid, Process{ .thread = thread_handle, .sender = channel, .parent_pid = parent_pid }) catch unreachable;
return pid;
},
// Rest of the ProcessManager methods...
};
pub fn main() !void {
var allocator = std.heap.page_allocator;
var pm = ProcessManager.new(&allocator);
// The initial process does not have a parent.
const pid1 = pm.fork(null, function1, 1);
// These processes are children of pid1.
const child1_of_pid1 = pm.fork(pid1, function2, 2);
const child2_of_pid1 = pm.fork(pid1, function3, 2);
// Scheduler simulation...
// Rest of the main function...
}
const std = @import("std");
const HashMap = std.AutoHashMap;
const Mutex = std.Thread.Mutex;
const Arc = std.atomic.AtomicRef;
const ProcessId = usize;
const Priority = u32;
const Message = extern enum {
Data: []const u8,
Terminate,
};
const Process = struct {
thread: ?std.Thread.Handle,
sender: ?std.Channel(Message),
};
const ProcessFunction = fn (?std.Channel(Message).Receiver) void;
const ProcessManager = struct {
processes: HashMap(ProcessId, Process),
next_pid: ProcessId,
priority_queue: Arc(Mutex([]ProcessId)),
pub fn new(allocator: *std.mem.Allocator) !ProcessManager {
return ProcessManager{
.processes = try HashMap(ProcessId, Process).init(allocator),
.next_pid = 1,
.priority_queue = try Arc.create(Mutex.init(try allocator.alloc(ProcessId, 1))),
};
},
pub fn fork(self: *ProcessManager, function: ProcessFunction, priority: Priority) !ProcessId {
const pid = self.next_pid;
self.next_pid += 1;
var channel = try std.Channel(Message).init(std.heap.page_allocator);
const thread_handle = try std.Thread.spawn(&channel.receiver, function);
try self.processes.put(pid, Process{ .thread = thread_handle, .sender = channel.sender });
var queue = try self.priority_queue.get().lock();
for (var i: u32 = 0; i < priority; i += 1) {
try queue.append(pid);
}
return pid;
},
pub fn send(self: *ProcessManager, pid: ProcessId, message: Message) void {
if (self.processes.get(pid)) |process| {
_ = process.sender.send(message);
}
},
pub fn schedule(self: *ProcessManager) void {
var queue = self.priority_queue.get().lock();
if (queue.pop()) |pid| {
self.send(pid, Message.Data("Running process due to scheduler"));
}
},
pub fn wait(self: *ProcessManager, pid: ProcessId) void {
if (self.processes.get(pid)) |process| {
if (process.thread) |thread| {
_ = thread.wait();
process.thread = null;
}
}
},
pub fn exit(self: *ProcessManager, pid: ProcessId) void {
self.send(pid, Message.Terminate);
_ = self.processes.remove(pid);
},
};
pub fn main() !void {
const allocator = std.heap.page_allocator;
var pm = try ProcessManager.new(allocator);
// Define process functions
const processFunction1 = processFunction1Impl;
const processFunction2 = processFunction2Impl;
const pid1 = try pm.fork(processFunction1, 1);
const pid2 = try pm.fork(processFunction2, 2);
// Scheduler simulation...
for (var i: usize = 0; i < 5; i += 1) {
pm.schedule();
std.time.sleep(std.time.milli(1000));
}
pm.wait(pid1);
pm.wait(pid2);
pm.exit(pid1);
pm.exit(pid2);
}
fn processFunction1Impl(receiver: ?std.Channel(Message).Receiver) void {
// Process 1 logic goes here
}
fn processFunction2Impl(receiver: ?std.Channel(Message).Receiver) void {
// Process 2 logic goes here
}
Talking to an SD Card
FAT
const std = @import("std");
const FatEntry = struct {
value: u32,
pub fn fromBytes(bytes: []const u8) FatEntry {
// Assuming little-endian format
return FatEntry{ .value = std.mem.readIntLittle(u32, bytes) };
}
};
const FakeDisk = struct {
data: []u8,
pub fn read(self: FakeDisk, start: usize, length: usize) []const u8 {
return self.data[start..][0..length];
}
pub fn write(self: *FakeDisk, start: usize, data: []const u8) void {
for (data, 0..) |byte, i| {
self.data[start + i] = byte;
}
}
};
const FatFileSystem = struct {
disk: FakeDisk,
fat_start: usize,
fat_entry_size: usize,
pub fn readFatEntry(self: FatFileSystem, index: u32) FatEntry {
const start = self.fat_start + (index * self.fat_entry_size);
const data = self.disk.read(start, self.fat_entry_size);
// This is a simplification. You'd need to handle different FAT versions (12, 16, 32) differently.
return FatEntry.fromBytes(data[0..4]);
}
};
pub fn main() void {
// Example usage
var diskData = [_]u8{0} ** 1024; // Initialize fake disk with 1KB of zeros
var fakeDisk = FakeDisk{ .data = diskData[0..] };
var fatFs = FatFileSystem{
.disk = fakeDisk,
.fat_start = 0,
.fat_entry_size = 4, // Assuming FAT32 for this example
};
const entry = fatFs.readFatEntry(0);
std.debug.print("FatEntry value: {}\n", .{entry.value});
}
init, shell, download, cat, ls, rm
Our operating system needs some userspace programs.
const std = @import("std");
const HashMap = std.StringHashMap;
const Allocator = std.mem.Allocator;
const FatEntry = struct {
value: u32,
};
const FakeDisk = struct {
data: []u8,
pub fn read(self: FakeDisk, start: usize, length: usize) []u8 {
return self.data[start .. start + length];
}
pub fn write(self: *FakeDisk, start: usize, data: []const u8) void {
for (data, 0..) |byte, i| {
self.data[start + i] = byte;
}
}
};
const FatFileSystem = struct {
disk: FakeDisk,
files: HashMap([]u32),
fat: []FatEntry,
pub fn new(allocator: *Allocator) !FatFileSystem {
return FatFileSystem{
.disk = FakeDisk{ .data = try allocator.alloc(u8, 1024 * 1024) }, // 1MB fake disk
.files = try HashMap([]u32).init(allocator),
.fat = &[_]FatEntry{},
};
}
pub fn init(self: *FatFileSystem) void {
self.files.deinit();
self.fat = &[_]FatEntry{};
}
pub fn ls(self: FatFileSystem) void {
var it = self.files.iterator();
while (it.next()) |entry| {
std.debug.print("{}\n", .{entry.key});
}
}
pub fn cat(self: FatFileSystem, filename: []const u8) void {
if (self.files.get(filename)) |fat_chain| {
for (fat_chain) |entry| {
std.debug.print("{}", .{self.disk.read(entry, 1)[0]});
}
std.debug.print("\n", .{});
} else {
std.debug.print("File not found\n", .{});
}
}
pub fn download(self: *FatFileSystem, src: []const u8, dest: []const u8) void {
if (self.files.get(src)) |fat_chain| {
self.files.put(dest, fat_chain) catch unreachable;
} else {
std.debug.print("Source file not found\n", .{});
}
}
pub fn rm(self: *FatFileSystem, filename: []const u8) void {
if (self.files.remove(filename)) |_| {
std.debug.print("File removed\n", .{});
} else {
std.debug.print("File not found\n", .{});
}
}
};
pub fn main() !void {
const allocator = std.heap.page_allocator;
var fs = try FatFileSystem.new(allocator);
var shell_active = true;
while (shell_active) {
var buffer: [1024]u8 = undefined;
const input = try std.io.getStdIn().readLine(buffer[0..]);
const tokens = std.mem.tokenize(input, " ");
switch (tokens.len) {
1 => switch (tokens[0]) {
"init" => fs.init(),
"ls" => fs.ls(),
"exit" => shell_active = false,
else => std.debug.print("Invalid command\n", .{}),
},
2 => switch (tokens[0]) {
"cat" => fs.cat(tokens[1]),
"rm" => fs.rm(tokens[1]),
else => std.debug.print("Invalid command\n", .{}),
},
3 => if (std.mem.eql(u8, tokens[0], "download")) {
fs.download(tokens[1], tokens[2]);
} else {
std.debug.print("Invalid command\n", .{});
},
else => std.debug.print("Invalid command\n", .{}),
}
}
}
Browser
Building a TCP stack
Kernel Networking Infrastructure
const std = @import("std");
const EthernetFrame = struct {
// ... Ethernet header fields ...
payload: std.ArrayList(u8), // ArrayList is used to represent a dynamic array in Zig
};
const IPPacket = struct {
// ... IP header fields ...
payload: std.ArrayList(u8),
};
const Packet = union(enum) {
Ethernet: EthernetFrame,
IP: IPPacket,
// ... other packet types ...
};
const NetworkInterface = struct {
// ... hardware-specific details ...
};
Ethernet driver integration
const std = @import("std");
const EthernetFrame = struct {
// ... Ethernet header fields ...
payload: std.ArrayList(u8), // ArrayList is used to represent a dynamic array in Zig
};
const IPPacket = struct {
// ... IP header fields ...
payload: std.ArrayList(u8),
};
const Packet = union(enum) {
Ethernet: EthernetFrame,
IP: IPPacket,
// ... other packet types ...
};
const NetworkInterface = struct {
// ... hardware-specific details ...
pub fn receivePacket(self: NetworkInterface) Packet {
_ = self;
// Integrate with the actual hardware driver to retrieve the packet
// Placeholder return, replace with actual logic
return Packet{ .Ethernet = EthernetFrame{ .payload = std.ArrayList(u8).init(std.heap.page_allocator) } };
}
pub fn sendPacket(self: NetworkInterface, packet: Packet) void {
_ = packet;
_ = self;
// Integrate with the hardware driver to send the packet
// Add logic here to handle packet sending
}
};
Networking Syscalls
const std = @import("std");
const IPAddress = struct {
// Define the IPAddress struct here.
};
const Socket = struct {
local_address: ?IPAddress,
remote_address: ?IPAddress,
// ... other socket state ...
pub fn send(self: Socket, data: []const u8) void {
_ = data;
_ = self;
// Serialize data into packets and use the network interface to send
}
pub fn recv(self: *Socket) []u8 {
_ = self;
// De-serialize received packets into data
// Placeholder return, replace with actual logic
return &[_]u8{}; // Return an empty slice or actual data
}
pub fn bind(self: *Socket, address: IPAddress) void {
self.local_address = address;
}
pub fn connect(self: *Socket, address: IPAddress) void {
self.remote_address = address;
// Implement the TCP handshake here
}
};
pub fn main() void {
// Example usage
var socket = Socket{
.local_address = null,
.remote_address = null,
};
_ = socket;
// Use the socket methods here...
}
telnetd, the power of being multiprocess
const std = @import("std");
pub fn main() !void {
const allocator = std.heap.page_allocator;
const listener = try std.net.TcpServer.init(23, allocator);
try listener.listen();
while (true) {
const client = try listener.accept();
_ = std.Thread.spawn(.{}, handleConnection, .{client}) catch continue;
}
}
fn handleConnection(client: std.net.TcpClient) void {
var buffer: [1024]u8 = undefined;
while (true) {
const n = client.read(&buffer) catch break;
if (n == 0) break;
const command = std.mem.trim(u8, buffer[0..n], "\0");
const output = executeCommand(command) catch continue;
client.writeAll(output) catch break;
}
}
fn executeCommand(command: []const u8) ![]u8 {
const process = try std.ChildProcess.init(command, std.heap.page_allocator);
defer process.deinit();
try process.spawn();
const output = try process.stdout.readAllAlloc(std.heap.page_allocator, std.math.maxInt(usize));
return output;
}
Dynamic Linking
Coding a Browser
const std = @import("std");
const http = @import("http"); // Hypothetical HTTP client module (you may need to implement or find a suitable library)
pub fn main() !void {
// Example URL
const url = "http://example.com";
// Fetch the content of the URL
var response = try fetchUrl(url);
std.debug.print("Fetched URL: {}\n", .{response});
// Process the fetched content (e.g., parse HTML, handle ANSI escape codes)
try processContent(response);
// Render the processed content to the terminal
try renderToTerminal(response);
}
fn fetchUrl(url: []const u8) ![]u8 {
// Implement or use a library function to fetch content from the URL
// For example, using a hypothetical http.get function
return http.get(url);
}
fn processContent(content: []u8) !void {
_ = content;
// Parse and process the HTML content
// This might involve stripping out HTML tags, converting to plain text, etc.
// You might also handle ANSI escape codes here for text formatting
}
fn renderToTerminal(content: []u8) !void {
_ = content;
// Render the processed content to the terminal
// This would include handling line breaks, text alignment, etc.
}